
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF意思是词频(Term Frequency),IDF意思是逆文本频率指数(Inverse Document Frequency)。 TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
 这个算法主要是参考了 TF-IDF与余弦相似性的应用(一):自动提取关键词
如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词("的"、"是"、"在")给予最小的权重,较常见的词("中国")给予较小的权重,较少见的词("蜜蜂"、"养殖")给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
下面就是这个算法的细节。
这个算法主要是参考了 TF-IDF与余弦相似性的应用(一):自动提取关键词
如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词("的"、"是"、"在")给予最小的权重,较常见的词("中国")给予较小的权重,较少见的词("蜜蜂"、"养殖")给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
下面就是这个算法的细节。
第一步,计算词频。
 考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。
考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。
 或者
或者

第二步,计算逆文档频率。
这时,需要一个语料库(corpus),用来模拟语言的使用环境。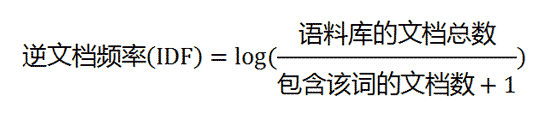 如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF。
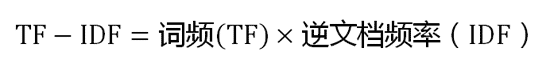 可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
还是以《中国的蜜蜂养殖》为例,假定该文长度为1000个词,"中国"、"蜜蜂"、"养殖"各出现20次,则这三个词的"词频"(TF)都为0.02。然后,搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
还是以《中国的蜜蜂养殖》为例,假定该文长度为1000个词,"中国"、"蜜蜂"、"养殖"各出现20次,则这三个词的"词频"(TF)都为0.02。然后,搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
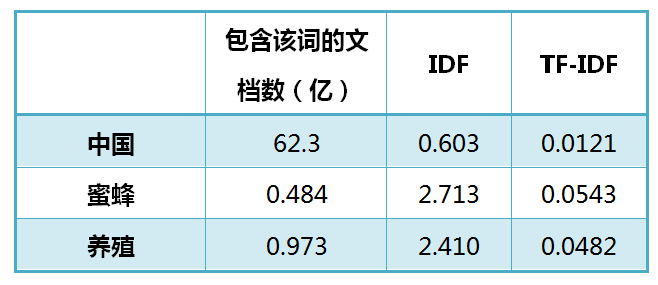 从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
除了自动提取关键词,TF-IDF算法还可以用于许多别的地方。比如,信息检索时,对于每个文档,都可以分别计算一组搜索词("中国"、"蜜蜂"、"养殖")的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
除了自动提取关键词,TF-IDF算法还可以用于许多别的地方。比如,信息检索时,对于每个文档,都可以分别计算一组搜索词("中国"、"蜜蜂"、"养殖")的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)

二,TF-IDF算法的计算步骤
第1步:计算逆文档频率
我们先统计各个词语被包含的文章数。比如“水果”被4篇文章(内容1、2、4、5)引用,4就是“水果”的逆文档频率。 分词后,各个单词的逆文档频率如下: 水果=4、苹果=3、好吃=2、菠萝=2、西瓜=2、梨子=2,桃子=1、猕猴桃=1、蔬菜=1,茄子=1 PS: IDF= log(语料库中的文件总数 / 包含词语 t 的文件数目),为了便于理解,这里做了精简。
按照我们的直觉,如果一篇文章把逆文档频率最高的前面的词都包含了,说明这篇文章内容更贴合用户意图,更受到搜索引擎喜欢。回到例子,"水果、苹果"是本例中重要性最高的2个词,如果内容中包含“水果、苹果”,那么这篇内容质量就越好。
所以把包含“水果、苹果”的内容拿出来,就是比较靠谱的内容了:
内容2: 水果有苹果,桃子,西瓜,菠萝,梨子
内容4: 苹果,梨子都是很好吃的水果
内容5: 好吃的水果有西瓜,苹果,葡萄,其他水果还有菠萝,猕猴桃
PS: IDF= log(语料库中的文件总数 / 包含词语 t 的文件数目),为了便于理解,这里做了精简。
按照我们的直觉,如果一篇文章把逆文档频率最高的前面的词都包含了,说明这篇文章内容更贴合用户意图,更受到搜索引擎喜欢。回到例子,"水果、苹果"是本例中重要性最高的2个词,如果内容中包含“水果、苹果”,那么这篇内容质量就越好。
所以把包含“水果、苹果”的内容拿出来,就是比较靠谱的内容了:
内容2: 水果有苹果,桃子,西瓜,菠萝,梨子
内容4: 苹果,梨子都是很好吃的水果
内容5: 好吃的水果有西瓜,苹果,葡萄,其他水果还有菠萝,猕猴桃
第2步:计算词频(TF)
我们把内容1、内容3砍掉了,剩下的内容2、内容4、内容5怎么排序。我们想一下,一个词语在内容中出现的次数越高,也说明这个词语对这篇文章更重要。回到本例,“水果”是我们的核心词,那么因为内容5中出现“水果”两次,内容2、内容4次数是1,那么内容5胜出。最后的排序结果如下 内容5: 好吃的水果有西瓜,苹果,葡萄,其他水果还有菠萝,猕猴桃 (第一名) 内容2: 水果有苹果,桃子,西瓜,菠萝,梨子(第二名) 内容4: 苹果,梨子都是很好吃的水果(第三名) 内容1: 水果有水果,水果,水果,水果,水果(相关度不够,被剔除) 内容3: 蔬菜都很好吃,我最爱吃茄子了( 相关度不够,被剔除 ) 以上是砍了又砍的TF-IDF算法简化解读版,真实的TFIDF算法比这个要正规复杂很多,这里只是让大家get到重点,码迷的目的就达到了。TF-IDF对SEO非常重要!
TF-IDF对SEO非常非常非常重要,重要的事情说三遍! 我们可以看到,TFIDF算法,不仅可以衡量关键词对页面的重要性,更能衡量文章的广度相关性。对于百度、360、google来说,TFIDF算法的出现屏蔽了一大批用关键词密度来获取排名的SEO小白,同时提升了搜索质量啊,真是一箭双雕。 百度百科里面说了:“除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。”。意思是什么?你排名可以由下面的公式决定。文章得分=TFIDF得分+链接得分,百度搜索引擎在用TFIDF!!如需转载请保留本文出处: https://www.zhe94.com/712.html



