简介
CDH是由Cloudera进行开发的大数据一站式平台管理解决方案,基于Hadoop生态的第三方发行版,通过基于Web的用户界面,支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop,简化了大数据平台的安装、使用难度。 CDH 是一个拥有集群自动化安装、中心化管理、集群监控、报警功能的一个工具(软件),使得集群的安装可以从几天的时间缩短为几个小时,运维难度低,极大的提高了集群管理的效率。大致架构图
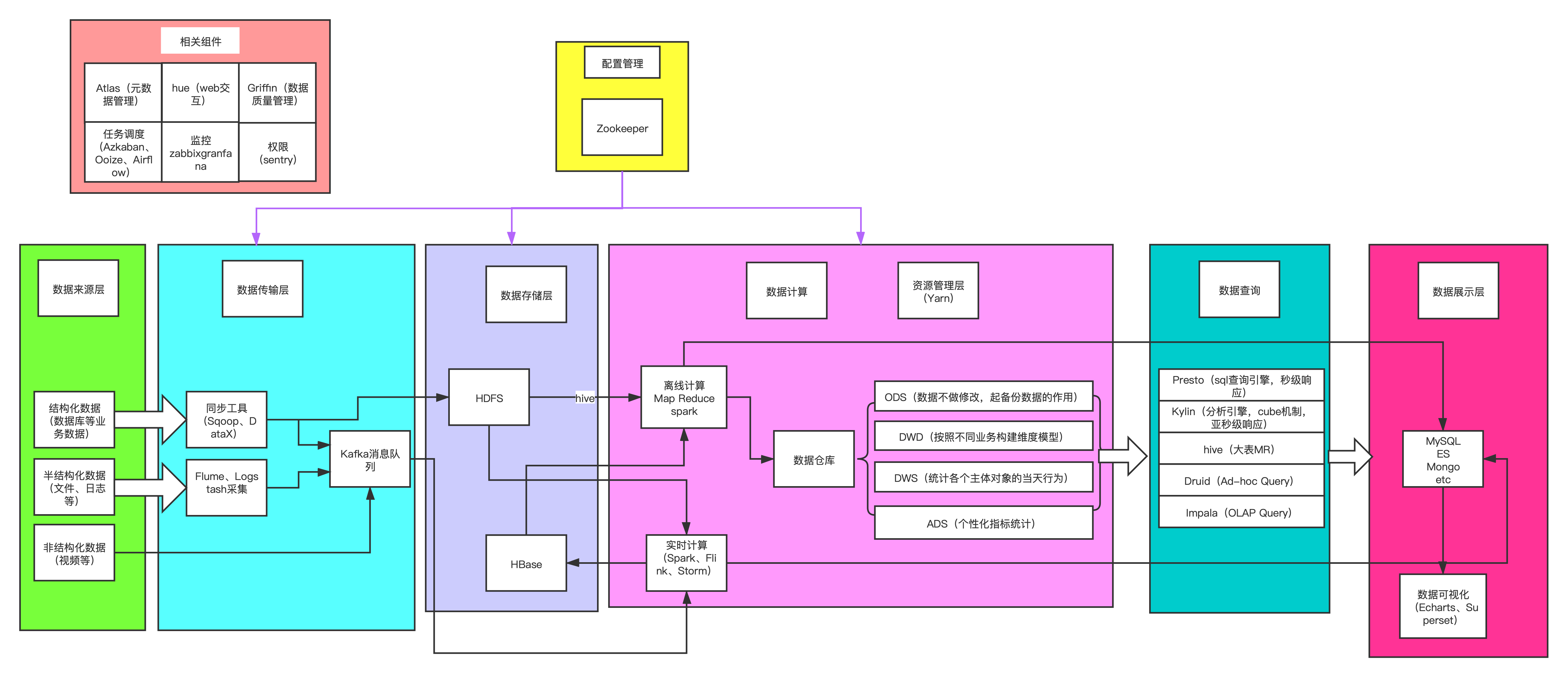 阐述
如上图,整体架构一些主要元素,如下做一些具体的阐述
包括大致的功能和想法等等
阐述
如上图,整体架构一些主要元素,如下做一些具体的阐述
包括大致的功能和想法等等
数据来源层
结构化数据:关系数据库,比如MySQL,即以关系数据库表形式管理的数据。 半结构化:非关系模型的、有基本固定结构模式的数据,例如日志文件、JSON文档等。 非结构化:没有固定模式的数据,如WORD、PDF、PPT、EXL,各种格式的图片、视频等。 比较大量的数据主要是半结构化的日志数据传输层
Sqoop:是一种主要用于在 Hadoop 和关系数据库之间传输数据的工具。可以将数据从关系型数据库(RDBMS)(比如MySQL)导入 Hadoop 分布式文件系统(HDFS),在 MP 中转换数据,然后将数据导出回 RDBMS。 DataX:作为一种离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer(读取/写入)插件,通过Framework纳入到整个同步框架中。 flume:是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,基本是CDH的标配。 logstash:是一个接收、处理、转发日志的工具,ELK当中的L。 Kafka:是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据,这边适配于大数据的lambda架构,通过实时topic和离线topic进行一定的区分。数据存储层
HDFS:分布式文件系统,大数据必备核心。 HBase:基于Hadoop之上提供了类似于Bigtable的能力,不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库;另一个不同的是HBase基于列的而不是基于行的模式。数据计算层:
MapReduce:是一种编程模型,用于大规模数据集(大于1TB)的并行运算,当然,随着现在计算力的提高,大多都开始走流式计算了。 Spark,flink,Storm:伪实时/实时计算引擎,逐步取代MapReduce数据查询层
Presto:facebook针对hive的优化版,可对250PB以上的数据进行快速地交互式分析,号称性能好十倍 Kylin:分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,提供亚秒级查询,帮助前端可以更实时的进行纬度分析以及报表查询。 Hive:hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。 1.1版本之后可以用MR或者Spark作为计算引擎 Druid:森林女神德鲁伊,可变身。。。。开玩笑的 大数据的Druid是一个高性能的实时分析型数据库,适合Ad-hoc Query场景查询。 Impala:能查询存储在Hadoop的HDFS和HBase中的PB级大数据。相比hive,Impala的最大特点也是最大卖点就是它的快速,很适合OLAP Query的场景。资源管理层
Yarn:是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,使得本身MapReduce不需要再承担资源调度的任务,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。属于绝对的核心服务。配置管理
Zookeeper:是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。相当于整个集群的配置基本都由这位动物园管理员来操作,属于绝对的核心服务。数据展示层
MySQL:关系型数据库,很多量不大的结果报表会走MySQL。CDH本身的节点信息管理也可以走MySQL,稳定的数据库,开源,社区强大,上手快。 ElasticSearch:ELK架构依然是日志分析的利器,ElasticSearch本身也支持OLAP的诸多查询场景,但成本确实是个问题。 Mongo:介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。bson结构的数据格式可以存储比较复杂的数据类型。 ECharts:是一款基于JavaScript的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表。 Superset:轻量级的数据查询和可视化方案,小规模数据的BI利器,多种数据库,包括 MySQL、PostgresSQL、Oracle、SQL Server、SQLite、SparkSQL 等,并深度支持 Druid。总结
上述描述了一些我接触到的软件,或有不全,后续会根据实际情况有所补充扩展。 现在很多大数据环境都也很不错,比如最近接触的阿里maxcompute+dataworks+flink+hologres的架构也可以解决不少问题。 来源:https://blog.51cto.com/u_14839701/2671702 <<从零开始-搭建CDH大数据集群>>如需转载请保留本文出处: https://www.zhe94.com/923.html


